{kind=link}

Democratising AI – Transfer learning wizard for energy machine learning applications
Daily life is getting exponentially more entangled with different applications of artificial intelligence (AI), and the energy domain is a key witness of such casualty, where AI applications will become the core technology to enable smart homes and smart grids, while helping us manage our power grids in a much more efficient way. Raise in popularity and demand of AI also increases the demand for AI trained engineers to help develop suitable models for different range of applications.
It is, however, important to remark that such raise of AI applications comes with a component of engagement across all stakeholders in the energy value chain, including of course the consumers for which, being realistic, an assumption of limited knowledge of AI must be taken. It is right here where the concept of democratization of AI shows up. The concept refers to the widespread access, adoption and utilization of AI technologies by all stakeholders involved, and empowers individuals, communities and organizations, regardless of their size or resources, to leverage AI tools and application to address energy-related challenges and promote sustainable practices. In other terms, the concept seeks to bring the benefits of AI to a broader range of participants, including end consumers.
Within the I-NERGY project, the concept of democratized AI has been present from the very beginning. Indeed, throughout the project we have addressed the challenge of developing a tool that can help unexperienced users to implement their own AI models. Such tool is called Transfer Learning Wizard (TLWizard). The tool is intended to support users clean their data, analyse it and then produce an AI model that can be used in the final user’s application. The TLWizard tool consists of two main components: a Graphical user interface (GUI), and a backend machine learning (ML) training step.
The TLWizard’s workflow is defined as a step-by-step guide that consists of three main steps:
(1) Data Analysis
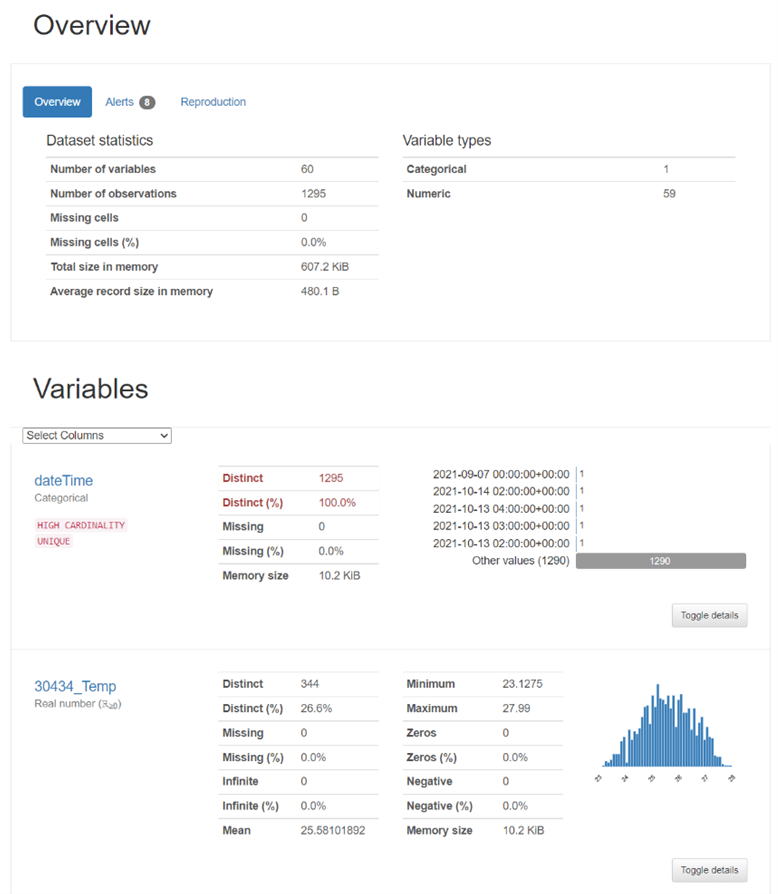
The users upload their data that will be used for training a ML model. The data can be uploaded either in CSV or Excel format. The tool then prompts the user to select the input features and target from the uploaded data. Next, a statistical analysis of the input features can be performed, where the user can analyse the correlation between the input features, detect missing data, and get general insights into the distribution and quality of the uploaded data.
(2) Model training
The ML model training takes place using the previously selected training features and target. The user's task is to define the problem type as either Classification, Regression, or Forecasting. Once the problem type is set, the training process begins. The TLWizard examines the shape and type of the input features, problem type, and target, and searches its internal model registry for a suitable model to fine-tune with the uploaded data. Then, using certain python libraries, the TLWizard builds the model registry.
If the TLWizard cannot find a suitable model in its registry, the user is notified and given the option to train a general model. In this case, one of the state-of-the-art time series-based architectures is employed based on the selected problem type. The model training follows an 80:20 approach, where 80% of the data is used for training, and the remaining 20% is used for evaluating the model's performance.
(3) Model evaluation
Once the model is trained, the TLWizard guides the user to the final step, where the evaluation results on the randomly selected 20% of the data are displayed. In the case of Classification problem type, the user is provided with the Precision, Recall and F1 score matrices, while for both Regression and Forecasting problem types, Mean Average Error, Mean Percentage Error, and Root Mean Squared error are displayed. Finally, the TLWizard prompts the users whether they will download the final model or try retraining the model.